">
一、 浏览器处理用户输入
1.1 识别URL
完整的URL包括以下几个部分,其中有的必须的,有的是可选的:
- 协议(e.g.
http,ftp) - 域名(e.g.
www.gogole.com) - 端口(e.g.
:80) - 文件路径(e.g.
/htm_data/20/1510/1441477.htm) - 参数(e.g.
?key1=value1&key2=value2) - 锚点(e.g.
#first-paragraph)
浏览器会根据识别出的协议发送请求。
当协议或主机名不合法时,浏览器会将地址栏中输入的文字传给默认的搜索引擎(即把用户输入看作是关键字)。大部分情况下,在把文字传递给搜索引擎的时候,URL会带有特定的一串字符,用来告诉搜索引擎这次搜索来自这个特定浏览器。
1.2 检查HSTS Preload List
HSTS的全称是HTTP Strict Transport Security(HTTP严格传输安全),它是一个Web安全策略机制(web security policy mechanism)。
在使用HTTP发送请求前,浏览器会检查自带的HSTS列表,这个列表里包含了那些请求浏览器只使用HTTPS进行连接的网站,如果网站在这个列表里,浏览器会使用 HTTPS 而不是 HTTP 协议,否则,最初的请求会使用HTTP协议发送
要申请将自己的站点加入到HSTS当中,可以访问https://hstspreload.org/
参考
二、 浏览器发送请求
在发送请求前,浏览器首先检查Web缓存,然后调用网络请求的方法。
2.1 DNS解析
读取本地DNS缓存
浏览器检查域名是否在缓存当中。如果使用本地缓存,则无DNS 查询,使用持久连接也是。
要查看Chrome中的DNS缓存,可以打开chrome://net-internals/#dns。
读取本地hosts文件
hosts文件文件负责将主机名称映射到相应的IP地址,通常用于补充或替换DNS的功能。用户可以直接对hosts文件进行控制。
要查看Linux中的hosts文件,可以访问/etc/hosts。
发送DNS解析请求
- 以
www.google.com为例,首先,客户端会向本地域名服务器发送DNS查询报文 - 本地域名转发请求给根域名服务器,后者会解析根域名
com,并返回对应顶级域名服务器的IP地址给前者 - 本地域名服务器访问负责com域名服务器,后者会解析顶级域名
google,然后返回对应权威域名服务器的IP地址给前者 - 本地余名服务器从负责解析
google的权威域名服务器处获取到www.google.com的IP地址,返回给客户端
DNS的解析是一个逐步缩小范围的查找过程。
2.2 建立连接
有了 IP 地址,就可以通过选择 TCP 或 UDP 协议来发送数据了。
这里需要补充一点的是,光靠 IP 地址是无法进行通信的,因为 IP 地址并不和某台设备绑定(比如使用了DHCP )。所以在底层通信时需要使用一个固定的地址,即结合MAC协议来建立连接。
建立TCP连接
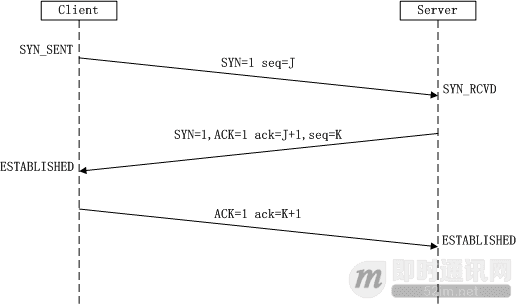
第一次握手:
- 客户端发送一个SYN标志位为1的包,指明客户打算连接的服务器的端口
- 设置初始序号ISN(即 J),保存在包头的序列号(Sequence Number)字段里
第二次握手:
- 服务器发回确认包(ACK)应答,即SYN标志位和ACK标志位均为1
- 设置序列号ISN(即K)
- 将确认序号ack设置为客户的ISN+1(即J+1)
第三次握手:
- 客户端再次发送确认包(ACK) SYN标志位为0,ACK标志位为1
- 把服务器发来ACK的序号字段+1(即K+1),放在确定字段ack中发送给对方
- 设置发送序号ISN(即J+1)
TCP的关键在于双方都需要确认自己的发信和收信功能正常,收信功能通过接收对方信息得到确认,发信功能需要发出信息—>对方回复信息得到确认。
要了解TCP如何断开连接,可以查看TCP三次握手四次挥手详解。
TLS握手
客户端发送一个
Client hello消息到服务器端,消息中同时包含了它的TLS版本,可用的加密算法和压缩算法。服务器端向客户端返回一个
Server hello消息,消息中包含了服务器端的TLS版本,服务器选择了哪个加密和压缩算法,以及服务器的公开证书,证书中包含了公钥。客户端会使用这个公钥加密接下来的握手过程,直到协商生成一个新的对称密钥客户端根据自己的信任CA列表,验证服务器端的证书是否有效。如果有效,客户端会生成一串伪随机数,使用服务器的公钥加密它。这串随机数会被用于生成新的对称密钥
服务器端使用自己的私钥解密上面提到的随机数,然后使用这串随机数生成自己的对称主密钥
客户端发送一个
Finished消息给服务器端,使用对称密钥加密这次通讯的一个散列值服务器端生成自己的 hash 值,然后解密客户端发送来的信息,检查这两个值是否对应。如果对应,就向客户端发送一个
Finished消息,也使用协商好的对称密钥加密从现在开始,接下来整个 TLS 会话都使用对称秘钥进行加密,传输应用层(HTTP)内容
SSL握手
2.3 发送请求
TCP连接建立后,浏览器就可以利用HTTP/HTTPS协议向服务器发送请求了。
HTTP协议
协议相关的内容这里不做展开介绍,要了解HTTP的相关内容可以参考MDN中HTTP的相关文档。
Web缓存
Web缓存是指一个Web资源(如html页面,图片,js,数据等)存在于Web服务器和客户端(浏览器)之间的副本。缓存会根据进来的请求保存输出内容的副本。
当下一个请求来到的时候,如果是相同的URL,缓存会根据缓存机制决定是直接使用副本响应访问请求,还是向源服务器再次发送请求。比较常见的就是浏览器会缓存访问过网站的网页,当再次访问这个URL地址的时候,如果网页没有更新,就不会再次下载网页,而是直接使用本地缓存的网页。只有当网站明确标识资源已经更新,浏览器才会再次下载网页。
浏览器端的缓存规则
对于浏览器端的缓存来讲,他们分别从新鲜度和校验值两个维度来规定浏览器是否可以直接使用缓存中的副本,还是需要去源服务器获取更新的版本。
新鲜度(过期机制):也就是缓存副本有效期。一个缓存副本必须满足以下条件,浏览器会认为它是有效的,足够新的:
- 含有完整的过期时间控制头信息(HTTP协议报头),并且仍在有效期内;
- 浏览器已经使用过这个缓存副本,并且在一个会话中已经检查过新鲜度;
满足以上两个情况的一种,浏览器会直接从缓存中获取副本并渲染。
校验值(验证机制):服务器返回资源的时候有时在控制头信息带上这个资源的实体标签Etag(Entity Tag),它可以用来作为浏览器再次请求过程的校验标识。如过发现校验标识不匹配,说明资源已经被修改或过期,浏览器需求重新获取资源内容。
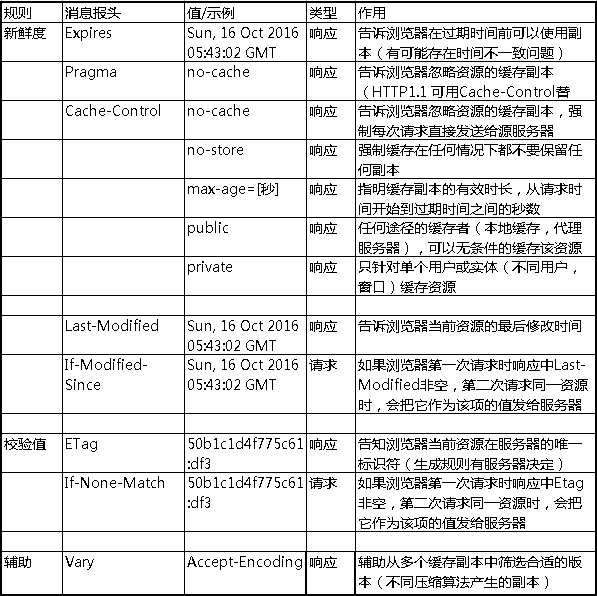
在HTTP请求和响应的消息报头中,常见的与缓存有关的消息报头有:
用户操作行为与缓存
用户在使用浏览器的时候,会有各种操作,这些行为会对缓存如下:
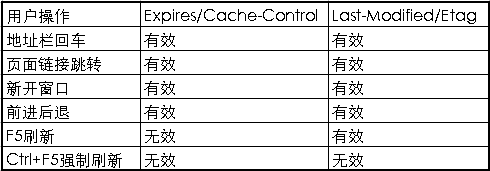
当用户在按F5进行刷新的时候,会忽略Expires/Cache-Control的设置,会再次发送请求去服务器请求,而Last-Modified/Etag还是有效的,服务器会根据情况判断返回304还是200;而当用户使用Ctrl+F5进行强制刷新的时候,只是所有的缓存机制都将失效,重新从服务器拉去资源。
参考
三、 服务端处理响应
3.1 负载均衡
请求在进入到真正的应用服务器前,可能还会先经过负责负载均衡的机器,它的作用是将请求合理地分配到多个服务器上,同时具备具备防攻击等功能。
负载均衡具体实现有很多种,有直接基于硬件的 F5,有操作系统传输层(TCP)上的 LVS,也有在应用层(HTTP)实现的反向代理(也叫七层代理),下面简单介绍一下。
LVS
LVS 的作用是从对外看来只有一个 IP,而实际上这个 IP 后面对应是多台机器,因此也被成为 Virtual IP。
前面提到的 NAT 也是一种 LVS 中的工作模式,除此之外还有 DR 和 TUNNEL,具体细节这里就不展开了,它们的缺点是无法跨网段,所以百度自己开发了 BVS 系统。
反向代理
反向代理是工作在 HTTP 上的,具体实现可以基于 HAProxy 或 Nginx,因为反向代理能理解 HTTP 协议,所以能做非常多的事情,比如:
- 进行很多统一处理,比如防攻击策略、防抓取、SSL、gzip、自动性能优化等
- 应用层的分流策略都能在这里做,比如对 /xx 路径的请求分到 a 服务器,对 /yy 路径的请求分到 b 服务器,或者按照 cookie 进行小流量测试等
- 缓存,并在后端服务挂掉的时候显示友好的 404 页面
监控后端服务是否异常
3.2 Web Server
请求经过前面的负载均衡后,将进入到对应服务器上的 Web Server/HTTP Daemon,比如 Apache、Tomcat、Node.JS 等。
以 Apache 为例,在接收到请求后会交给一个独立的进程来处理,可以通过编写 Apache 或调用 PHP 等脚本语言来进行处理。一般网站都会基于某个 Web 框架来开发,因此在后端语言执行时首先进入 Web 框架的代码,然后由框架再去调用应用的实现代码。
大致过程如下:
HTTPD 接收请求
服务器把请求拆分为以下几个参数:
- HTTP 请求方法(
GET,POST,HEAD,PUT,DELETE,CONNECT,OPTIONS, 或者TRACE)。直接在地址栏中输入 URL 这种情况下,使用的是 GET 方法 - 域名:google.com
请求路径/页面:/ (我们没有请求google.com下的指定的页面,因此 / 是默认的路径)
服务器验证其上已经配置了 google.com 的虚拟主机
服务器验证 google.com 接受 GET 方法
服务器验证该用户可以使用 GET 方法(根据 IP 地址,身份信息等)
如果服务器安装了 URL 重写模块(例如 Apache 的 mod_rewrite 和 IIS 的 URL Rewrite),服务器会尝试匹配重写规则,如果匹配上的话,服务器会按照规则重写这个请求
服务器根据请求信息获取相应的响应内容,这种情况下由于访问路径是 “/“ ,会访问首页文件(你可以重写这个规则,但是这个是最常用的)。
服务器会使用指定的处理程序分析处理这个文件,假如 Google 使用 PHP,服务器会使用 PHP 解析 index 文件,并捕获输出,把 PHP 的输出结果返回给请求者
Web Server还会涉及到数据的读写,这部分就不做展开说明了。
参考
四、浏览器接收并处理响应
浏览器的功能是从服务器上取回请求的资源,然后展示在浏览器窗口当中。资源通常是 HTML 文件,也可能是 PDF,图片,或者其他类型的内容。下面以请求一个网页为例进行介绍。
4.1 浏览器接收响应
内容编码
浏览器发送请求时,会通过 Accept-Encoding 带上自己支持的内容编码格式列表;服务端从中挑选一种用来对正文进行编码,并通过 Content-Encoding 响应头指明选定的格式。
浏览器拿到响应正文后, Content-Encoding 进行解压。当然,服务端也可以返回未压缩的正文,但这种情况不允许返回 Content-Encoding。这个过程就是 HTTP 的内容编码机制。
在 HTTP/1 中,头部始终是以 ASCII 文本传输,没有经过任何压缩,因此内容编码仅仅是针对请求的正文部分。这个问题在 HTTP/2 中得以解决。
要了解HTTP内容编码,可以参考HTTP压缩,浏览器是如何解析的。
注:不要把内容编码(Conent-Encoding)与传输编码(Transfer-Encoding)混淆了
4.2 浏览器基本结构
在说明浏览器如何解析资源之前,先对浏览器的基本组件做一个简单的介绍:
- 用户界面
- 浏览器引擎 在用户界面和呈现渲染之间传送指令
- 网络组件 用于网络调用,比如 HTTP 请求。其接口与平台无关,并为所有平台提供底层实现
- 用户界面后端 用于绘制基本的窗口小部件,比如组合框和窗口。其公开了与平台无关的通用接口,而在底层使用操作系统的用户界面方法
- 数据存储 浏览器需要在硬盘上保存各种数据,例如 Cookie。新的 HTML 规范 (HTML5) 定义了“网络数据库”,这是一个完整(但是轻便)的浏览器内数据库

4.3 解析和DOM树构建
当服务器提供了资源之后(HTML,CSS,JS,图片等),浏览器会就执行下面的操作:
解析 —— HTML,CSS,JS
渲染 —— 构建 DOM 树 -> 渲染 -> 布局 -> 绘制
HTML解析
CSS解析
JS解析
4.4 呈现树的构建
4.5 布局与绘制
参考